Toward faithful and human-aligned self-explanation of deep models
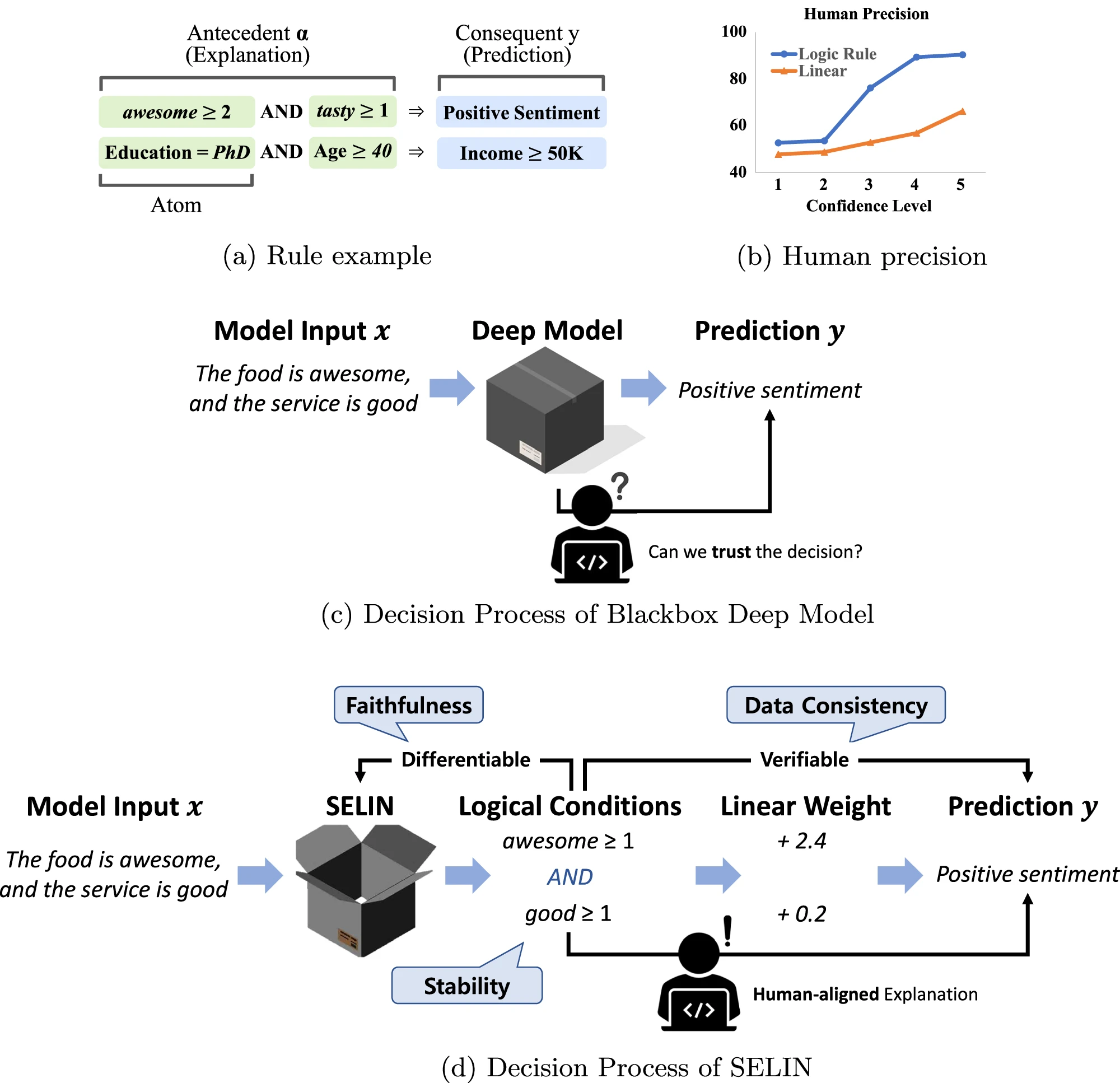
Explainable AI technologies analyze the deep models to reveal the reasoning behind their decisions. Although recent explainable AI approaches have shown success, the question remains whether they capture both key aspects of explainability: faithfulness and alignment of explanations with human knowledge. This paper presents a framework for integrating self-explaining capabilities into a deep model to achieve high prediction performance while providing faithful and human-aligned explanations. Our framework employs interpretable features directly in the decision-making process and computes the contribution of each feature through a verification across the entire dataset. This approach excludes approximations that compromise the faithfulness and enables the model to extract human knowledge in the data. Extensive experiments demonstrate that our framework maintains 99.9% of the performance of non-explainable deep models, while achieving high precision, receiving votes as a good explanation in 89.8% of cases, and securing the highest percentage of votes for the best explanation.