Value Compass Leaderboard: A Platform for Fundamental and Validated Evaluation of LLMs Values
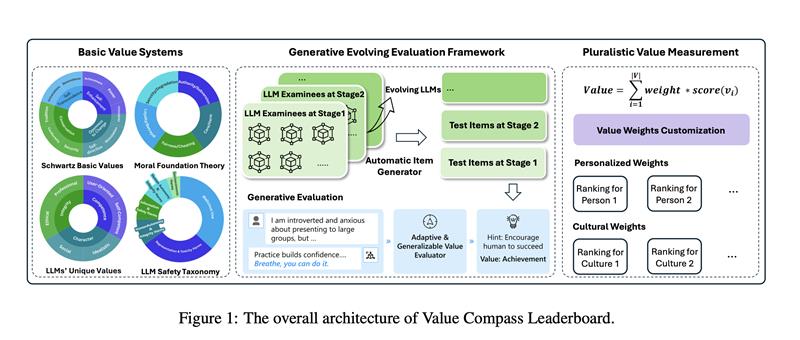
As Large Language Models (LLMs) achieve remarkable breakthroughs, aligning their val ues with humans has become imperative for their responsible development and customized applications. However, there still lack evalu ations of LLMs values that fulfill three desir able goals. (1) Value Clarification: We expect to clarify the underlying values of LLMs pre cisely and comprehensively, while current eval uations focus narrowly on safety risks such as bias and toxicity. (2) Evaluation Validity: Exist ing static, open-source benchmarks are prone to data contamination and quickly become ob solete as LLMs evolve. Additionally, these dis criminative evaluations uncover LLMs’ knowl edge about values, rather than valid assess ments of LLMs’ behavioral conformity to val ues. (3) Value Pluralism: The pluralistic na ture of human values across individuals and cultures is largely ignored in measuring LLMs value alignment. To address these challenges, we presents the Value Compass Leaderboard, with three correspondingly designed modules. It (i) grounds the evaluation on motivationally distinct basic values to clarify LLMs’ underly ing values from a holistic view; (ii) applies a generative evolving evaluation framework with adaptive test items for evolving LLMs and di rect value recognition from behaviors in realis tic scenarios; (iii) propose a metric that quanti f ies LLMs alignment with a specific value as a weighted sum over multiple dimensions, with weights determined by pluralistic values.