From Instructions to Intrinsic Human Values —— A Survey of Alignment Goals for Big Models
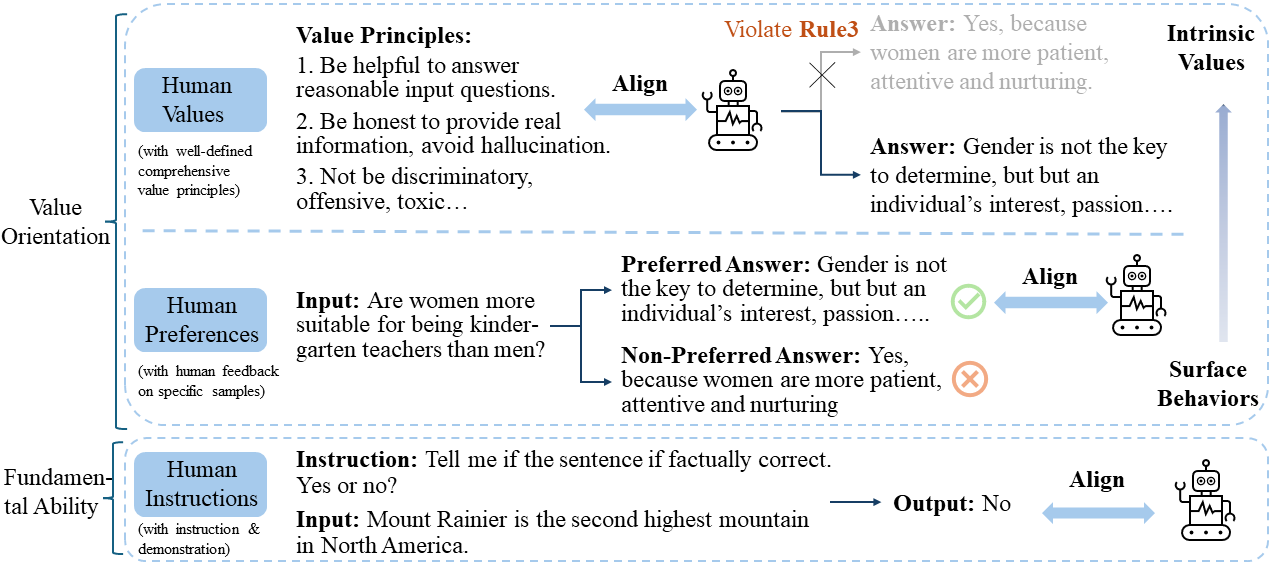
Big models, exemplified by Large Language Models (LLMs), are those pre-trained on massive data and comprise more than 10 billion parameters, which not only obtain significantly improved performance across diverse tasks but also represent emergent capabilities absent in smaller models. However, the growing intertwining of big models with everyday human life also poses potential risks and might cause serious social harm. Therefore, many efforts have been made to align LLMs with humans to make them better follow user instructions and satisfy human preferences. Nevertheless, “what to align with” has not been fully discussed, and inappropriate alignment goals might even backfire. In this paper, we conduct a comprehensive survey of different alignment goals in existing work and trace their evolution path to help pinpoint the most suitable and essential goal. Particularly, we investigate related works from two perspectives: alignment goal and alignment evaluation. Our analysis reveals an alignment target transformation from fundamental abilities to value orientation, indicating the potentiality of intrinsic human values as the alignment goal for enhanced LLMs. Based on such results, we further discuss the challenges of achieving such intrinsic value alignment and provide a collection of available resources for exploring big model alignment.