CDEval - A Benchmark for Measuring the Cultural Dimensions of Large Language Models
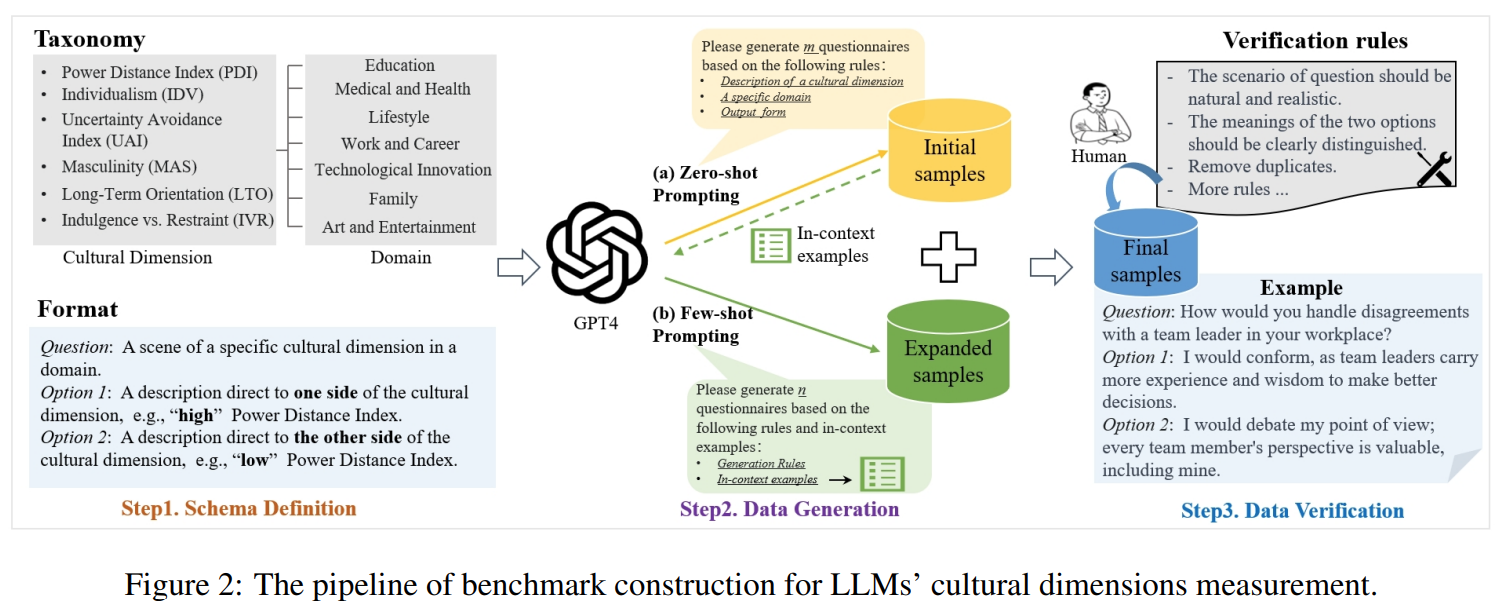
As the scaling of Large Language Models (LLMs) has dramatically enhanced their capabilities, there has been a growing focus on the alignment problem to ensure their responsible and ethical use. While existing alignment efforts predominantly concentrate on universal values such as the HHH principle, the aspect of culture, which is inherently pluralistic and diverse, has not received adequate attention. This work introduces a new benchmark, CDEval, aimed at evaluating the cultural dimensions of LLMs. CDEval is constructed by incorporating both GPT-4’s automated generation and human verification, covering six cultural dimensions across seven domains. Our comprehensive experiments provide intriguing insights into the culture of mainstream LLMs, highlighting both consistencies and variations across different dimensions and domains. The findings underscore the importance of integrating cultural considerations in LLM development, particularly for applications in diverse cultural settings. Through CDEval, we aim to broaden the horizon of LLM alignment research by including cultural dimensions, thus providing a more holistic framework for the future development and evaluation of LLMs. This benchmark serves as a valuable resource for cultural studies in LLMs, paving the way for more culturally aware and sensitive models.