Elephant in the Room - Unveiling the Impact of Reward Model Quality in Alignment
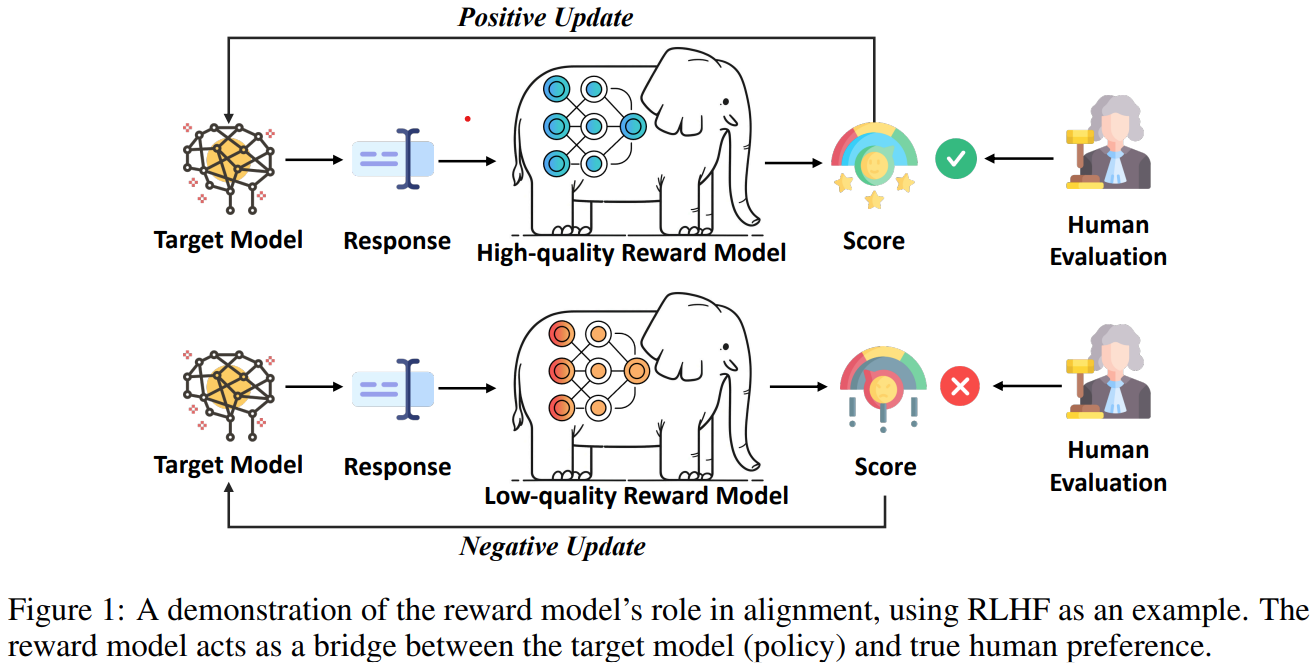
The demand for regulating potentially risky behaviors of large language models (LLMs) has ignited research on alignment methods. Since LLM alignment heavily relies on reward models for optimization or evaluation, neglecting the quality of reward models may cause unreliable results or even misalignment. Despite the vital role reward models play in alignment, previous works have consistently overlooked their performance and used off-the-shelf reward models arbitrarily without verification, rendering the reward model ``\emph{an elephant in the room}’’. To this end, this work first investigates the quality of the widely-used preference dataset, HH-RLHF, and curates a clean version, CHH-RLHF. Based on CHH-RLHF, we benchmark the accuracy of a broad range of reward models used in previous alignment works, unveiling the unreliability of using them both for optimization and evaluation. Furthermore, we systematically study the impact of reward model quality on alignment performance in three reward utilization paradigms. Extensive experiments reveal that better reward models perform as better human preference proxies. This work aims to awaken people to notice this huge elephant in alignment research. We call attention to the following issues: (1) The reward model needs to be rigorously evaluated, whether for alignment optimization or evaluation. (2) Considering the role of reward models, research efforts should not only concentrate on alignment algorithm, but also on developing more reliable human proxy.